Monitor API Health Check with Prometheus

𝐖𝐡𝐨 𝐈 𝐚𝐦
Bobur is a developer advocate and speaker specializing in software and data engineering. With over 10- years of experience in IT, he blogs about open-source technologies and the community around them.
𝐖𝐡𝐚𝐭 𝐈 𝐝𝐨
I work with companies at different scales to build awareness, drive adoption, and engage with the community for your developer-targeted products. I also create inspiring content, design, and code use cases, projects, and demo apps to boost learning your product.
APISIX has a health check mechanism, which proactively checks the health status of the upstream nodes in your system. Also, APISIX integrates with Prometheus through its plugin that exposes upstream nodes (multiple instances of a backend API service that APISIX manages) health check metrics on the Prometheus metrics endpoint typically, on URL path /apisix/prometheus/metrics.
In this post, we’ll guide you on how to enable and monitor API health checks using APISIX and Prometheus.
Prerequisite(s)
This guide assumes the following tools are installed locally:
Before you start, it is good to have a basic understanding of APISIX. Familiarity with API gateway, and its key concepts such as routes, upstream, Admin API, plugins, and HTTP protocol will also be beneficial.
Docker is used to install the containerized etcd and APISIX.
Install cURL to send requests to the services for validation.
Start the APISIX demo project
This project leverages existing the pre-defined Docker Compose configuration file to set up, deploy and run APISIX, etcd, Prometheus, and other services with a single command. First, clone the apisix-prometheus-api-health-check repo on GitHub and open it in your favorite editor, and start the project by simply running docker compose up from the project root folder.
When you start the project, Docker downloads any images it needs to run. You can see the full list of services in docker-compose.yaml file.
Add health check API endpoints in upstream
To check API health periodically, APISIX needs an HTTP path of the health endpoint of the upstream service. So, you need first to add /health an endpoint for your backend service. From there, you inspect the most relevant metrics for that service such as memory usage, database connectivity, response duration, and more. Assume that we have two backend REST API services web1 and web2 running using the demo project and each has its own health check endpoint at the URL path /health. At this point, you do not need to make additional configurations. In reality, you can replace them with your backend services.
The simplest and standardized way to validate the status of a service is to define a new health check endpoint like
/healthor/status
Setting Up Health Checks in APISIX
This process involves checking the operational status of the ‘upstream’ nodes. APISIX provides two types of health checks: Active checks and Passive Checks respectively. Read more about Health Checks and how to enable them here. Use the Admin API to create an Upstream object. Here is an example of creating an Upstream object with two nodes (Per each backend service we defined) and configuring the health check parameters in the upstream object:
curl "http://127.0.0.1:9180/apisix/admin/upstreams/1" -H "X-API-KEY: edd1c9f034335f136f87ad84b625c8f1" -X PUT -d '
{
"nodes": {
"web1:80": 1,
"web2:80": 1
},
"checks": {
"active": {
"timeout": 5,
"type": "http",
"http_path": "/health",
"healthy": {
"interval": 2,
"successes": 1
},
"unhealthy": {
"interval": 1,
"http_failures": 2
}
}
}
}'
This example configures an active health check on the /health endpoint of the node. It considers the node healthy after one successful health check and unhealthy after two failed health checks.
Note that sometimes you might need the IP addresses of upstream nodes, not their domains (
web1andweb2) if you are running services outside docker network. It is by design that the health check will be started only if the number of nodes (resolved IPs) is bigger than 1.
Enable the Prometheus Plugin
Create a global rule to enable the prometheus plugin on all routes by adding "prometheus": {} in the plugins option. APISIX gathers internal runtime metrics and exposes them through port 9091 and URI path /apisix/prometheus/metrics by default that Prometheus can scrape. It is also possible to customize the export port and URI path, add extra labels, the frequency of these scrapes, and other parameters by configuring them in the Prometheus configuration /prometheus_conf/prometheus.ymlfile.
curl "http://127.0.0.1:9180/apisix/admin/global_rules" -H "X-API-KEY: edd1c9f034335f136f87ad84b625c8f1" -X PUT -d '{
"id": "rule-for-metrics",
"plugins": {
"prometheus":{}
}
}'
Create a Route
Create a Route object to route incoming requests to upstream nodes:
curl "http://127.0.0.1:9180/apisix/admin/routes/1" -H "X-API-KEY: edd1c9f034335f136f87ad84b625c8f1" -X PUT -d '
{
"name": "backend-service-route",
"methods": ["GET"],
"uri": "/",
"upstream_id": "1"
}'
Send validation requests to the route
To generate some metrics, you try to send a few requests to the route we created in the previous step:
curl -i -X GET "http://localhost:9080/"
If you run the above requests a couple of times, you can see from responses that APISX routes some requests to node2 and others to node2. That’s how Gateway load balancing works!
hello web2
HTTP/1.1 200 OK
Content-Type: text/plain; charset=utf-8
Content-Length: 10
Connection: keep-alive
Date: Sat, 22 Jul 2023 10:16:39 GMT
Server: APISIX/3.3.0
...
hello web1
Collecting health check data with the Prometheus plugin
Once the health checks and route are configured in APISIX, you can employ Prometheus to monitor health checks. APISIX automatically exposes health check metrics data for your APIs if the health check parameter is enabled for upstream nodes. You will see metrics in the response after fetching them from APISIX:
curl -i http://127.0.0.1:9091/apisix/prometheus/metrics
Example Output:
# HELP apisix_http_requests_total The total number of client requests since APISIX started
# TYPE apisix_http_requests_total gauge
apisix_http_requests_total 119740
# HELP apisix_http_status HTTP status codes per service in APISIX
# TYPE apisix_http_status counter
apisix_http_status{code="200",route="1",matched_uri="/",matched_host="",service="",consumer="",node="172.27.0.5"} 29
apisix_http_status{code="200",route="1",matched_uri="/",matched_host="",service="",consumer="",node="172.27.0.7"} 12
# HELP apisix_upstream_status Upstream status from health check
# TYPE apisix_upstream_status gauge
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.5",port="443"} 0
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.5",port="80"} 1
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.7",port="443"} 0
apisix_upstream_status{name="/apisix/upstreams/1",ip="172.27.0.7",port="80"} 1
Health check data is represented with metrics label apisix_upstream_status. It has attributes like upstream name, ip and port. A value of 1 represents healthy and 0 means the upstream node is unhealthy.
Visualize the data in the Prometheus dashboard
Navigate to http://localhost:9090/ where the Prometheus instance is running in Docker and type Expression apisix_upstream_status in the search bar. You can also see the output of the health check statuses of upstream nodes on the Prometheus dashboard in the table or graph view:
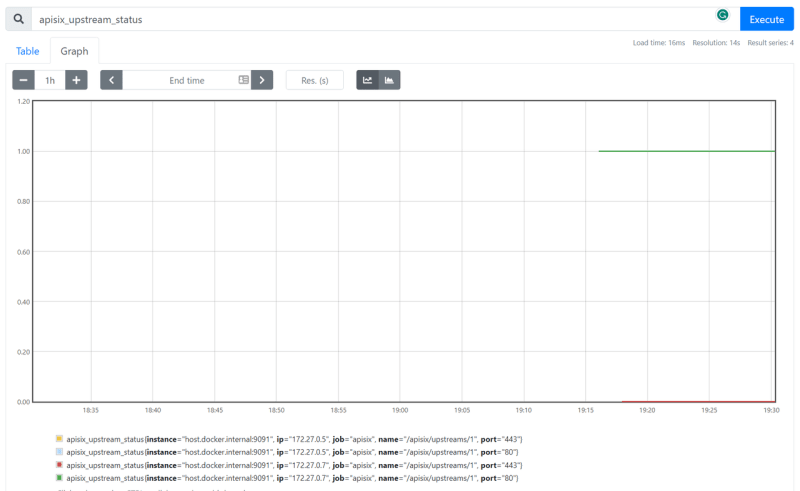
Cleanup
Once you are done experimenting with Prometheus and APISIX Gateway health check metrics, you can use the following commands to stop and remove the services created in this guide:
docker compose down
Next Steps
You have now learned how to set up and monitor API health checks with Prometheus and APISIX. APISIX Prometheus plugin is configured to connect Grafana automatically to visualize metrics. Keep exploring the data and customize the Grafana dashboard by adding a panel that shows the number of active health checks.



